Concurrency Control in QLDB
- 10 minutes read - 2101 wordsBackground
Concurrency control is critical in any system where accuracy and trust in the record needs to be maintained. It is the way of ensuring that correct results are generated, even when multiple concurrent transactions are taking place.
This blog post takes a closer look at how Amazon QLDB implements concurrency control. It includes a number of demos that you can try out for yourself, with more information and the code available at QLDB Concurrency Demo
ACID Properties and Isolation Levels
QLDB is fully ACID-compliant when it comes to database transactions. These four properties cover the following:
- Atomic - either all operations in a transaction are committed, or they are rolled back.
- Consistent - all data written to the database must be valid according to defined rules such as constraints
- Isolated - transactions cannot intefere with each other
- Durable - successfully committed transactions are persisted and can survive a system failure
Ensuring the correct isolation is the main goal of concurrency control. In ANSI SQL there are four standard isolation levels:
- Read Uncommitted - one transaction may read uncommitted changes from another transaction
- Read Committed - briefly acquires locks during reads, whilst maintaining write locks until transaction is committed
- Repeatable Read - acquires and holds both read and write locks until transaction is committed
- Serializable - uses range-locks to prevent new rows being added if they match a where clause to prevent phantom reads
The higher the level of isolation, the worse the performance is due to lock contention. QLDB provides a form of serializable isolation level, but uses Optimistic Concurrency Control (OCC), which operates on the principle that multiple transactions can frequently compete without intefering with each other. Using OCC, transactions in QLDB don’t acquire locks on database resources and operate with full serializable isolation. QLDB executes concurrent transactions in a serial manner, such that it produces the same effect as if those transactions were executed serially.
Before committing, each transaction performs a validation check to ensure that no other committed transaction has modified the snapshot of data that it’s accessing. If this check reveals conflicting modifications, or the state of the data snapshot changes, the committing transaction is rejected. However, the transaction can be restarted.
When a transaction writes to QLDB, the validation checks of the OCC model are implemented by QLDB itself. If a transaction can’t be written to the journal due to a failure in the verification phase of OCC, QLDB returns an OccConflictException to the application layer. The application software is responsible for ensuring that the transaction is restarted. The application should abort the rejected transaction and then retry the whole transaction from the start.
So why might data have changed between when it is first read to when an update is applied? QLDB is a journal-first database. Transactions are first written to the journal, and then ‘indexed storage’ is updated to reflect these changes. All writes go to the journal-first, whereas reads go from indexed storage. In the examples that follow, when a query is first made, it is querying indexed storage, which may or may not yet reflect the result of a write. In practice, the QLDB indexed storage is usually instantly up to date. This means as a developer, there is no reason to take a lock or check rows updated with a condition. Concurrency in QLDB is simple - write your code as if you’re the only actor in the system and ensure the operations are committed.
Executing a transaction against QLDB
The primary method of executing a transaction against a QLDB ledger is the executeLambda method on the QLDB driver.
await qldbDriver.executeLambda(async (txn) => {
...
});
All database operations within this method are atomic, and will only be committed once all the code is executed. If there is a failure, the driver will retry the entire execution block. It is possible to specify the maximum number of retries, as well as backoff strategies. For a great article on these concepts, read Timeouts, retries, and backoff with jitter from the Amazon Builders Library.
Custom Retry and Backoff config
There are 3 options for providing custom retry and backoff config. The QLDB driver will use the following precedence when selecting the Retry Config for a given transaction:
-
Use custom Retry Config provided in the
executeLambdamethodThis allows you to specify unique config for each function as shown below.
await qldbDriver.executeLambda(async (txn) => {
...
}, new RetryConfig(2));
-
Use custom Retry Config provided during the
QLDBDriverinitialisationThis allows you to specify behaviour that will apply where #1 is not set
function createQldbDriver(
ledgerName = "qldb-concurrency",
serviceConfigurationOptions = {},
) {
//Use driver's default backoff function (and hence, no second parameter provided to RetryConfig)
const retryConfig = new RetryConfig(4);
const maxConcurrentTransactions = 10;
const qldbDriver = new QldbDriver(ledgerName, serviceConfigurationOptions, maxConcurrentTransactions, retryConfig);
return qldbDriver;
}
-
Use the default Retry Config provided by the driver
The current default value of
retryLimitis 4. This will be used when #1 and #2 are not set
QLDB Concurrency Control Examples
Now with this understanding, we get to the fun part of executing operations against QLDB to understand the behaviour.
Demo 1 - Create Duplicate Customer Record
In this first demo, we create a table called Customer that has no indexes on it. We want to make sure that an email address is unique, so when we create a new customer record, we check to see if that email address already exists, and if not we create the customer record. In addition, we also add the unique id of the document as a guid attribute to the document. This results in 3 separate database operations. After checking that the email is unique, we pause execution for 10 seconds.
let attempts = 0;
await qldbDriver.executeLambda(async (txn) => {
console.log('Attempt: ' + ++attempts);
// Check if the record already exists assuming email unique for demo
const recordsReturned = await checkEmailUnique(txn, email);
if (recordsReturned === 0) {
console.log(`About to pause for ${delay} milliseconds`)
await sleep(delay);
const recordDoc = [{name, email, phoneNumber}]
// Create the record. This returns the unique document ID in an array as the result set
const result = await createRecord(txn, recordDoc);
const docIdArray = result.getResultList()
const docId = docIdArray[0].get("documentId").stringValue();
// Update the record to add the document ID as the GUID in the payload
await addGuid(txn, docId, email);
}
}, new RetryConfig(2));
During this period, we kick off another transaction that inserts this record. The result of this
Attempt: 1
In checkEmailUnique function with email: matt@test.com
No records found for matt@test.com
About to pause for 10000 milliseconds
In the createRecord function with doc: [object Object]
In the addGuid function with docId: 2EOl5jE9nIlBycoHUltIxX and email: matt@test.com
Attempt: 2
In checkEmailUnique function with email: matt@test.com
Record already exists for matt@test.com
We can show this visually in the flow diagram below:
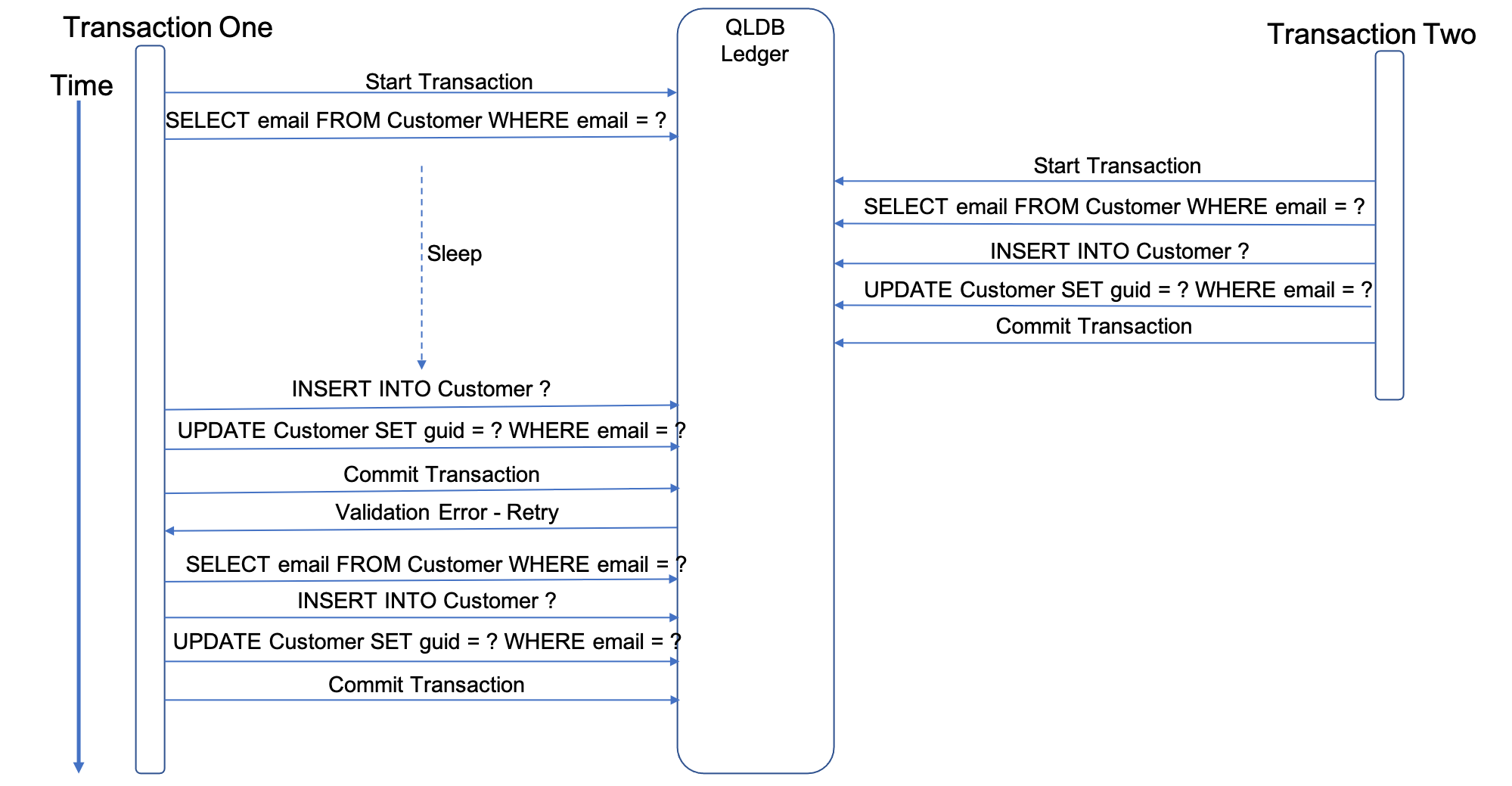
What we can see from this is that the original commit fails, as the QLDB driver recognises the snapshot of data its accessing has been changed, and so retries the entire transaction block. This time around, the first select operation identifies the email is not unique, and so no updates are made.
Note that if we explicitly change the RetryConfig to 0, to instruct the QLDB driver not to retry the transaction, we will receive back an OccConflictException that the client needs to handle:
OccConflictException: Optimistic concurrency control (OCC) failure encountered while committing the transaction
message: 'Optimistic concurrency control (OCC) failure encountered while committing the transaction',
code: 'OccConflictException',
time: 2021-03-31T21:18:13.741Z,
requestId: 'GZKrELsH5c8DUVwZQNNilO, GZKrELsH5c8DUVwZQNNilO',
statusCode: 400,
retryable: false
Demo 2 - Create Customer Record
The second demo, is the same as the first demo, apart from the second transaction is creating a different customer record. This results in the following output:
Attempt: 1
In checkEmailUnique function with email: matt@test.com
No records found for matt@test.com
About to pause for 10000 milliseconds
In the createRecord function with doc: [object Object]
In the addGuid function with docId: 8KKV8h80qQqHCrLEJKG1Mb and email: matt@test.com
In the updateTelephone function with telephone: 01234567 and email: matt@test.com
Attempt: 2
In checkEmailUnique function with email: matt@test.com
No records found for matt@test.com
About to pause for 10000 milliseconds
In the createRecord function with doc: [object Object]
In the addGuid function with docId: 9mov0fkSUqZ0wrn83488BF and email: matt@test.com
In the updateTelephone function with telephone: 01234567 and email: matt@test.com
In QLDB, each transaction is committed as a block to the journal. This journal block contains transaction metadata, along with entries for each document revision made, and the corresponding PartiQL statements that committed them. You can query the committed view of a document to find out its strandId and sequenceNo in the block, and then use these details to call the QLDB get-block CLI command to retrieve the contents of that block. The following is a subset of the information contained in the block record for this operation:
{
"Block": {
"IonText": "{
blockAddress:{
strandId:\"Cn7mGwi40kd5DGDECsOccv\",
sequenceNo:58
},
...
transactionInfo:{
statements:[
{
statement:\"SELECT email FROM Customer WHERE email = ?\",
startTime:2021-04-04T21:04:42.095Z,
statementDigest:{{tYw/7Uma7cru0ZUOAdY0TLmAseaJ5fuvB88a/mMxjP8=}}
},
{
statement:\"INSERT INTO Customer ?\",
startTime:2021-04-04T21:04:52.249Z,
statementDigest:{{5EgmnGIocHe7yfzvPPXWetoVmnYpHzU6yLtuGJMvbDY=}}
},
{
statement:\"UPDATE Customer as b SET b.guid = ? WHERE b.email = ?\",
startTime:2021-04-04T21:04:52.363Z,
statementDigest:{{9ZMrlsiQHaQwRp8Jlyk8OZdKxDKdoCzGktrabQKk98E=}}
}
],
documents:{
'9mov0fkSUqZ0wrn83488BF':{
tableName:\"Customer\",
tableId:\"Fskf3bYaBglLPSN72m2Es6\",
statements:[1,2,3]
}
}
},
...
}"
}
}
You can see that all PartiQL statements are shown. You can also see the 10 second different in the statement start times as a result of the sleep.
The biggest issue is the fact the QLDB driver retried the whole transaction as a result of another update to the same table taking place at the same time, even though it was for a different record. This is important to bear in mind when searching on an unindexed attribute. Other transactions can carry out select statements on the same table which will not cause a retry. However, if another transaction has created a new record or updated an existing record in the same table that this transaction has searched against, it will cause a retry to take place. Now lets see what happens if we add an index to the table.
Demo 3 - Create Customer Record with Index
The third demo, is the same as the second demo, apart from the fact an index is first created on the Customer table on the email attribute. This now results in the following output:
Attempt: 1
In checkEmailUnique function with email: matt@test.com
No records found for matt@test.com
About to pause for 10000 milliseconds
In the createRecord function with doc: [object Object]
In the addGuid function with docId: 5kelU9q5mdRGfn0mCVQc96 and email: matt@test.com
In the updateTelephone function with telephone: 01234567 and email: matt@test.com
This time, with an index on the Customer table, the QLDB driver does not attempt to retry the transaction. This reinforces the critical recommendation to always use select queries that make use of indexes. Without this, it will result in a full table scan which will result in slow queries. Futhermore, as we saw in demo 2, it may result in a higher number of OCC Exceptions.
Demo 4 - Timeout
The fourth demo is similar to any of the first 3, but the delay is set to a minimum of 30 seconds. This will result in the following:
InvalidSessionException: Transaction I1pH6SCujBW0JYpPoLQT02 has expired
...
message: 'Transaction I1pH6SCujBW0JYpPoLQT02 has expired',
code: 'InvalidSessionException',
time: 2021-04-05T21:06:46.935Z,
requestId: '4SnOdtcgpur5MmhXFEV3iE, 4SnOdtcgpur5MmhXFEV3iE',
statusCode: 400,
retryable: false
}
A transaction can run for up to 30 seconds before being committed. After this timeout, any work done on the transaction is rejected, and QLDB discards the session. This limit protects the client from leaking sessions by starting transactions and not committing or cancelling them.
Conclusion
So there we have it. Hopefully you have learnt more about how QLDB handles concurrency control. The key takeaways are:
- You can configure custom retry and backoff behaviour for all transactions when instantiating the QLDB driver, which can be overridden for each individual transaction in the
executeLambdafunction. Otherwise, the default settings are used - All database operations in the QLDB driver
executeLambdafunction are committed or rolled back atomically - The QLDB driver will perform a validation check before committing the transaction. If not valid, the driver will retry all database operations in the transaction again up to the retry limit
- Always use an index when selecting a record from a table. Otherwise, not only will a full table scan take place adding latency, but it will result in more OCC Exceptions as all records in the table will be in the snapshot validated by the driver
- A transaction can be active for up to 30 seconds, after which time it will be rejected. Make sure to limit the number of long running database operations within a transaction to prevent this.